前言
本文介绍几种最常用的几种索引优化手段
- 联合索引;
- 最左前缀索引;
- 调整索引列顺序;
- 索引覆盖;
- 普通索引和唯一索引,如何选择;
- 三星索引;
联合索引
在建立索引的时候,尽量在多个单列索引上判断下是否可以使用联合索引
联合索引的优点
- 不仅可以节省空间,还可以更容易的使用到索引覆盖。
- 索引的字段越多,更容易满足查询需要返回的数据。 例如联合索引(a_b_c),等价于有了三个索引:a,a_b,a_b_c,索引树的叶节点数据没变,索引data字段数据是省数据了。
创建原则
- 将频繁使用、区分度高的列放在联合索引前面,区分度高代表筛选粒度大,也可以将经常需要作为查询返回的字段增加到联合索引中,放在联合索引尾部。
- 如果在联合索引上增加一个字段而使用到了覆盖索引(索引下推),避免回表,就建议使用联合索引。
使用场景
- 考虑当前是否已经存在多个可以合并的单列索引,如果有,将当前多个单列索引创建为一个联合索引。
- 当前索引存在频繁使用作为返回字段的列,可以考虑当前列是否可以加入到当前已经存在的索引上,使其查询语句可以使用到覆盖索引,而不用回表查询。
最左前缀原则
最左前缀原则与联合索引的索引存储结构和检索方式有关。
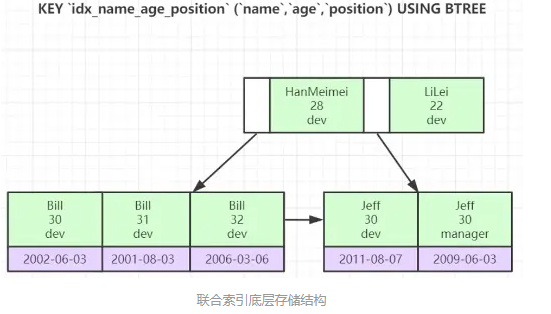
如上图,在联合索引树上,最底层的叶子节点按照第一列name从左到右递增排列,但是age和position是无序的,age只有在name值相等的情况下,小范围内递增有序,而position列只有在name和age两列相等的情况下小范围内递增有序。
select * from abc_innodb where name = 'haha' and age = 30 and position = 'dev';
像这个查询,B+树会比较name列来确定下一步搜索方向,往左还是右,如果name列相同再比较age列。如果查询条件没有name列,B+树就不知道第一步应该从哪个节点查起。
select * from abc_innodb where name like 'Bi%';
如果你要查的是所有名字以'Bi'为前缀的人,也能够用上这个索引,查找到第一个符合条件的记录,然后向后遍历,直到不满足条件为止。
所以,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
例如对于BLOG、TEXT和VARCHAR类型的列,必须使用前缀索引,只索引开始的部分字符。
调整索引列顺序
基于上面对最左前缀索引的说明,讨论一个问题:在建立联合索引的时候,如何安排索引内的字段顺序。
评估标准是,索引的复用能力。因为可以支持最左前缀,所以当已经有了 (a,b) 这个联合索引后,一般就不需要单独在 a 上建立索引了。因此,第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
要为高频请求创建 (身份证号,姓名)这个联合索引,并用这个索引支持 "根据身份证号查询地址" 的需求。
那么,如果既有联合查询,又有基于 a、b 各自的查询呢?查询条件里面只有 b 的语句,是无法使用 (a,b) 这个联合索引的,这时候不得不维护另外一个索引,也就是说需要同时维护 (a,b)、(b) 这两个索引。
覆盖索引
定义:索引包含所有需要查询的字段的值,避免回表。
覆盖索引是一种很常用的优化手段。因为在使用辅助索引的时候,我们只可以拿到主键值,相当于获取数据还需要再根据主键查询主键索引再获取到数据。
但是试想下这么一种情况,在上面abc_innodb表中的组合索引查询时,如果我只需要abc字段的,那是不是意味着我们查询到组合索引的叶子节点就可以直接返回了,而不需要回表。这种情况就是覆盖索引。
普通索引和唯一索引, 如何选择
结论是:如无特殊需求, 尽量选择普通索引。
可以从查询和更新过程的区别考虑。
查询过程区别
对于普通索引来说,查找到满足条件的第一个记录 (5,500) 后,需要查找下一个记录,直到碰到第一个不满足 k=5 条件的记录。
对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
两者性能区别微乎其微。 因为InnoDB 的数据是按数据页为单位来读写的。也就是说,当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。在 InnoDB 中,每个数据页的大小默认是 16KB。 即使普通索引需要继续往后查找,能在同一页内停止搜索概率还是很大的。
更新过程区别
当更新操作涉及唯一索引时,因为唯一性约束,当数据不在内存页时,不能使用change buffer直接更新,必须将数据从磁盘中加载。 而普通索引则没有这个限制。 所以,这两类索引在查询能力上是没差别的,主要考虑的是对更新性能的影响。所以,尽量选择普通索引。
三星索引
在日常的数据库优化中,通过索引来优化往往是最常用的方法之一,三星索引是提炼出索引设计的准则和原理。
第一颗星:与查询相关的索引行是相邻的,也就是where后面的等值谓词,可以匹配索引列顺序 一般我们把选择性高的列放在前面,把范围查询的字段放在后面,这样仅需要扫描更少的索引就能定位我们想要的数据。
第二颗星:索引行的顺序与查询语句需求一致,也就是order by 中的排序和索引顺序是否一致 避免排序,如果结果集采用现有顺序读取,那么就会避免一次排序
第三颗星:索引行包含查询语句中所有的列 避免每一个索引行查询,都需要去聚簇索引进行一次随机IO查询
练习1 - 关于最左前缀匹配
有以下联合索引 (a,b,c), 以下哪些语句可以使用该联合索引
1. select * from table where a = xxx and b = xxx; 2. select * from table where a = xxx and c = xxx; 3. select * from table where b = xxx; 4. select * from table where a = xxx and b = xxx order by c; 5. select * from table where a = xxx order by c;
答案是: 1,2,4,5;
练习2 - 如何判断三星索引以及改造
参考
三星索引介绍: https://blog.csdn.net/Zhuxiaoyu_91/article/details/127178101
达成例子
现有表
mysqlCREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(100) NOT NULL DEFAULT '', `age` int(11) NOT NULL DEFAULT '0', `sex` tinyint(4) NOT NULL DEFAULT '0', `weight` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=301 DEFAULT CHARSET=utf8mb4
建立索引 key(name,age,sex,weight) 对于下面SQL,是个三星索引
mysqlselect weight,age from student where name = 'xx' and age = yy order by sex;
分析如下: 第一颗星: 所有等值谓词的列(name,age),是组合索引的开头的列,可以把索引片缩得很窄,符合。 第二颗星: order by 的 sex字段在组合索引中且是索引自动排序好的,符合。 第三颗星: select的weight, age字段在组合索引中存在,符合。
未达成例子
同样是上面的table, 建立索引 key(name,age,sex) 对应下面SQL
mysqlselect name,age,sex from student where name like 'test%' and age = 23 order by sex
第一颗星: where xxx 满足; 第二颗星: 不满足, 因为name采用范围匹配而不是等值匹配, age是过滤列, 此时sex列无法保证有序; 第三颗星: 满足, 查询的数据均在索引列;
变更列顺序, 重新建立索引 key(age,sex,username), 分析 第一颗星: 不满足, 只可以匹配到age, 不能匹配name, 是个宽片索引; 第二颗星: 满足,等值age情况下, sex是有序的; 第三颗星: 满足, 查询的数据均在索引列;
在大多数情况下,能够满足2颗星,就已经可以缩小很大的查询范围,具体要保留哪颗星(排序星 or 窄索引片星), 需要查询者自行决定。
哪颗星最重要
第三颗星, 回表可能会导致很多磁盘读,第一和第二颗星重要星差不多,第二颗星重要度是50%,第一为27%,第二为23%.
一次性更改所有类似单词 CTRL+SHIFT+L
https://zhuanlan.zhihu.com/p/341534303
将光标移到行的末尾和开头 ALT+SHIFT+L
https://zhuanlan.zhihu.com/p/341534303
将当前屏幕纵向分屏 CTRL+\
设置主题
阮一峰博客
https://www.ruanyifeng.com/blog/2019/09/curl-reference.html
有用的例子
curl发送POST请求, 并且带上两个Header参数
curl -d '{"login": "emma", "pass": "123"}' -H 'Content-Type: application/json' -H 'type:haha' https://google.com/login
打印响应体的header
curl -i https://www.baidu.com
利用curl命令返回值确定地址是否正常
curl -s https://www.baidu.com
上面命令一旦发生错误,不会显示错误信息。不发生错误的话,会正常显示运行结果。
参数补充说明
| 参数 | 用途 |
|---|---|
| -m/--max-time | 设置请求超时的时间 |
| -w/--write-out | 以固定特殊的格式输出,例如:%{http_code},输出状态码 |
获取请求 地址响应状态码(200表示正常)
curl -I -m 5 -s -w "%{http_code}\n" -o /dev/null www.baidu.com
插入数据, 当数据重复时执行更新, 同时更新操作时间
table设计如下:
| userid(int) | score(int) | update_time(datetime) |
|---|---|---|
| 10001 | 100 | 2023-05-27 |
| 10002 | 99 | 2023-05-26 |
假设每日要导入分数有变更的用户, 当用户为第1次导入时, 正常insert, 否则直接对score进行更新, 同时更新操作时间, SQL如下
sqlinsert into tbname (userid, score, update_time) values (%d, %d, '%s')
on duplicate key update score = %d, update_time = now()
背景
工作中总会遇到服务器磁盘空间不足问题, 本文记录排查思路
排查过程
一. 查看根目录文件夹占用大小
shelldu -lh --max-depth=1 /
二. 进入文件夹容量大, 继续执行查看当前目录下各子文件夹大小指令
shelldu -lh --max-depth=1 ./
三. 定位到占用空间大的文件夹后, 按大小降序列出当前目录文件
shelldu -sh * | sort -nr
四. 执行相关文件删除, 选择空间占用大的, 或者旧文件进行删除
方法一: 删除指定天数前修改过的文件
shellfind /data/logs -mtime +92 -type f -name *.log -exec rm -rf {} \;
方法二: 清空指定文件
手动将 /dev/null 这个"黑洞"文件复制到指定文件
shellcp /dev/null ./nohup.out
